Domain Adaptation Components¶
This page contains more details on each component of the Domain Adaptation
framework, and example usage of transformers_domain_adaptation classes.
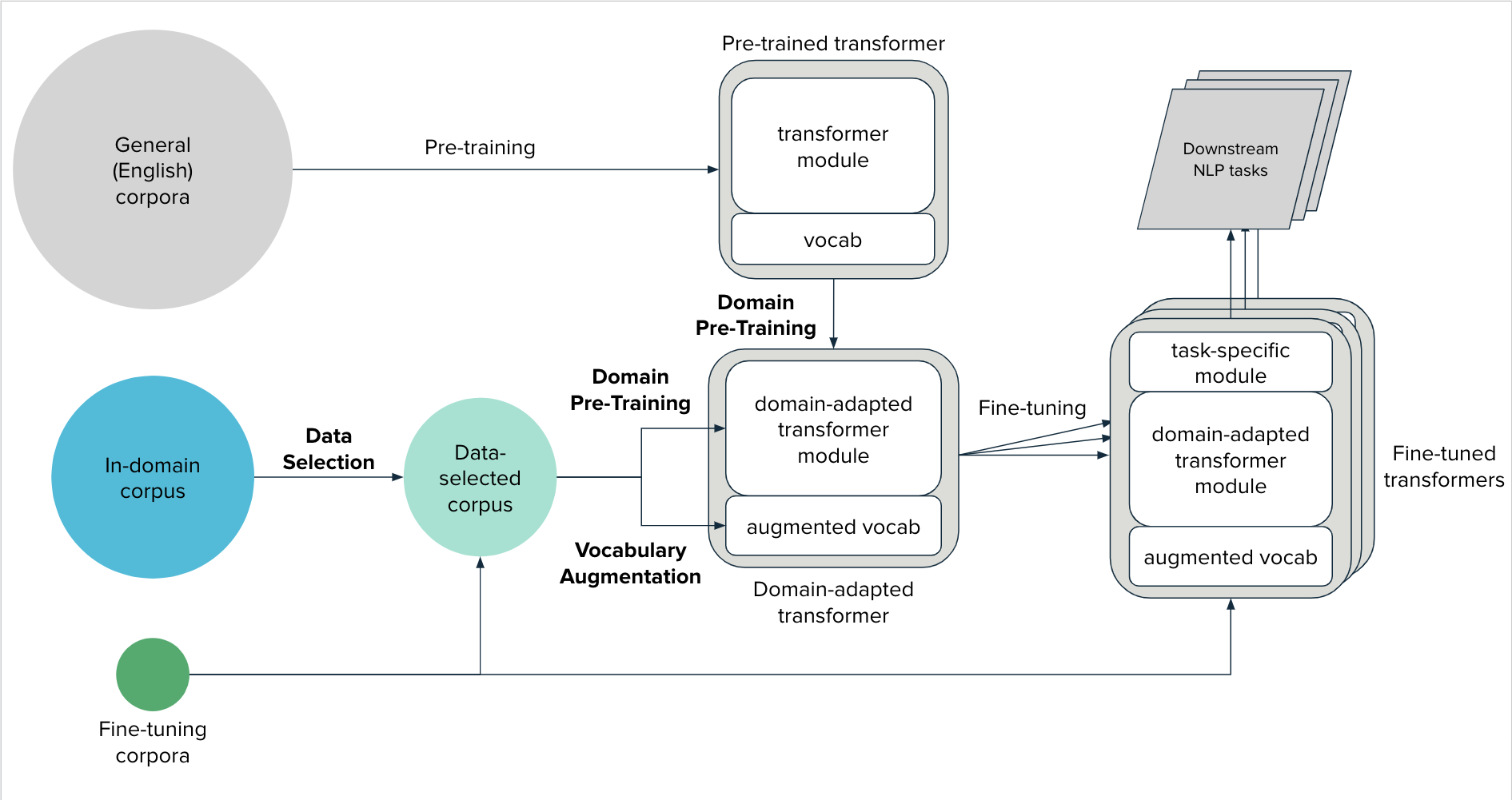
Data Selection¶
The size and scope of domain of the in-domain corpus tends to be larger than those of the fine-tuning corpora. As a result, it is expected that there will more documents that are irrelevant and noisy / of low-quality. Such irrelevant documents, at best, merely lengthen training time without boosting performance. At worst, they also degrade the transformer model’s performance in what is known as catastrophic forgetting.
Ruder and Plank [1] proposed two sets of statistical metrics to quantify the relevance of a given document:
- Similarity
Relevant documents have term distributions that closely resembles that of a reference document/corpus.
- Diversity
Documents that contain rare or highly discriminative terms may contain useful semantics that may benefit model training.
Procedure
Calculate similarity and diversity metric scores for each document in the in-domain corpus.
Emulating Ruder and Plank [1], obtain a document’s relevance score by normalizing each metric independently before summing them up.
Rank documents by their relevance scores and select the most relevant documents.
Note
For the full list of similarity and diversity metrics, please refer to Data Selection Metrics.
This toolkit provides a DataSelector class that encapsulates the logic above.
from pathlib import Path
from transformers_domain_adaptation import DataSelector
selector = DataSelector(
keep=0.5, # Keep the 50% most relevant documents
tokenizer=tokenizer,
similarity_metrics=['euclidean'],
diversity_metrics=["type_token_ratio", "entropy"],
)
# Load text data into memory
fine_tuning_texts = Path(ft_corpus_train).read_text().splitlines()
training_texts = Path(dpt_corpus_train).read_text().splitlines()
# Learn term distribution of the fine-tuning corpus
selector.fit(fine_tuning_texts)
# Select documents from in-domain training corpus
# that are relevant to the fine-tuning corpus
selected_corpus = selector.transform(training_texts)
Vocabulary Augmentation¶
Transformers use subword tokenization algorithms — Byte-Pair Encoding (BPE), WordPiece or Unigram — to tokenize text data. The vocabulary of a transformer’s tokenizer is created by training on general (English) corpora. This vocabulary can be extended with domain-specific terminology. By doing so, transformers can explicitly learn representations of key and frequently occuring terms in the target domain.
Furthermore, the vocabulary is extended, rather replaced with an in-domain vocabulary trained from scratch, in order to leverage the rich pre-trained term representations of the existing vocabulary.
Procedure
Given an existing vocabulary \(V\), train a new vocabulary \(V_domain\) on the fine-tuning corpora using the transformer’s corresponding tokenization algorithm.
Select the most frequent new vocabulary terms, \(T\), that appear in the fine-tuning corpora and are not already present in \(V\).
Extend \(V\) with new terms \(T\).
Update transformer’s embedding layer’s shape to account for newly added terms.
The VocabAugmentor class is provided
to easily perform the procedure above.
It finds domain-specific terms to extend an existing tokenizer’s vocabulary to the target_vocab_size:
from typing import List
from transformers_domain_adaptation import VocabAugmentor
target_vocab_size = 31_000 # len(tokenizer) == 30_522
augmentor = VocabAugmentor(
tokenizer=tokenizer,
cased=False,
target_vocab_size=target_vocab_size
)
# Obtain new domain-specific terminology based on the fine-tuning corpus
new_tokens: List[str] = augmentor.get_new_tokens("fine_tuning_corpus.txt")
assert len(new_tokens) == (target_vocab_size - len(tokenizer))
# Update ``model`` and ``tokenizer`` with these newfound terms
tokenizer.add_tokens(new_tokens)
model.resize_token_embeddings(len(tokenizer))
assert len(tokenizer) == target_vocab_size
assert model.get_input_embeddings().shape[1] == target_vocab_size
Domain Pre-Training¶
Domain pre-training follows the same unsupervised pre-training procedure of a given transformer model. The distinction is that domain pre-training utilizes a (data selected) in-domain corpus and may include the use of an augmented vocabulary.
This step has three purposes:
It allows for better representation of existing terms in the context of the target domain. For example, domain pre-training disambiguates terms such as “squash” — which can be a plant, an action or a sport — based on the target domain.
To learn representations of the newly added domain-specific terms in the augmented vocabulary.
To generate output sentence embeddings that are more aligned with the target domain.
A model can be domain-adapted using HuggingFace’s Trainer and TrainingArguments classes:
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(...)
trainer = Trainer(
model=model, # transformer model to be domain-adapted
args=training_args,
...
)
trainer.train()