Introduction¶
Transformers Domain Adaptation improves the performance of HuggingFace transformer models on downstream NLP tasks, by domain-adapting models to the target domain of said NLP tasks (e.g. BERT -> LawBERT).
Use Case¶
The typical approach to train a transformer model for a given NLP task (e.g. document classification, NER, summarization, etc.) is to fine-tune a pre-trained transformer model. While that has been effective, our research has shown that better model performance can be achieved by first domain-adapting the base transformer model to the domain of the dowsntream NLP task(s).
- This toolkit will be useful to you, if:
the language domain is niche or technical
there exist proprietary or additional, unlabelled text corpora in the given domain to train on
there are multiple NLP tasks in the same domain
By domain-adapting a transformer model once, it can be used as better starting point to fine-tune on multiple downstream NLP tasks.
The Domain Adaptation Framework¶
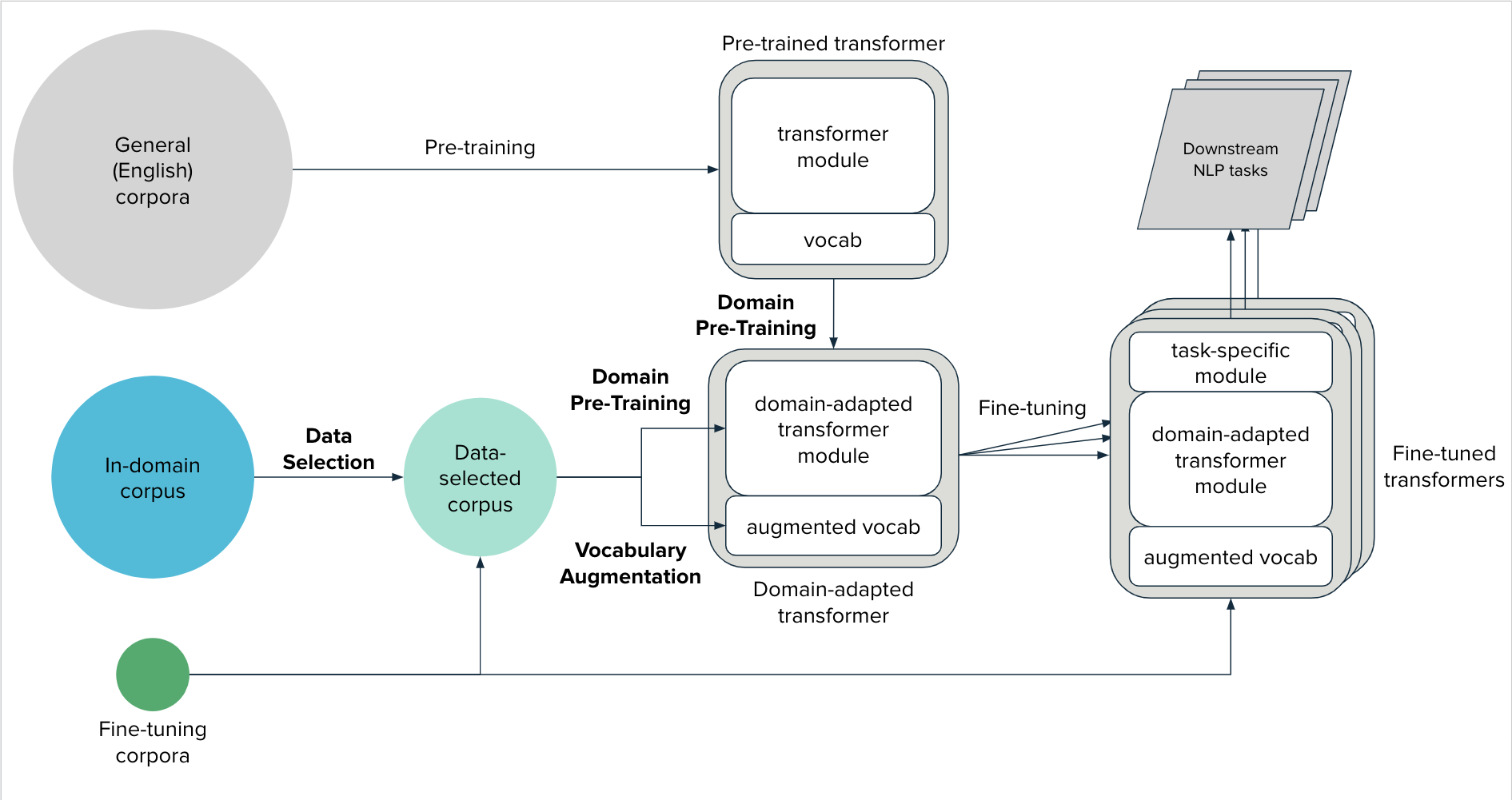
Corpora Types¶
- In-domain corpus
Unlabelled text data in the given language domain of the downstream NLP task(s). The domain itself may be broader than the language domain of the task(s). This corpus is typically larger than the fine-tuning corpora and can be noisier and contain less relevant documents.
- Fine-tuning corpus/corpora
Text data from the fine-tuning task(s) which can aid Data Selection and Vocabulary Augmentation
Overview¶
On a high-level, the Domain Adaptation framework can be broken down into three components:
- Data Selection
Select a relevant subset of documents from the in-domain corpus that is likely to be beneficial for domain pre-training (see below)
- Vocabulary Augmentation
Extending the vocabulary of the transformer model with domain specific-terminology
- Domain Pre-Training
Continued pre-training of transformer model on the in-domain corpus to learn linguistic nuances of the target domain
More details on each of these phases can be found in Domain Adaptation Components.
Todo
Link to arXiv paper